JVM
内存模型 #
方法区 #
JVMS: The Java Virtual Machine has a method area that is shared among all Java Virtual Machine threads. The method area is analogous to the storage area for compiled code of a conventional language or analogous to the “text” segment in an operating system process. It stores per-class structures such as the run-time constant pool, field and method data, and the code for methods and constructors, including the special methods (§2.9) used in class and instance initialization and interface initialization.
The method area is created on virtual machine start-up. Although the method area is logically part of the heap, simple implementations may choose not to either garbage collect or compact it. This specification does not mandate the location of the method area or the policies used to manage compiled code. The method area may be of a fixed size or may be expanded as required by the computation and may be contracted if a larger method area becomes unnecessary. The memory for the method area does not need to be contiguous.
翻译:Java虚拟机有一个在所有Java虚拟机线程之间共享的方法区域。方法区域类似于传统语言编译代码的存储区域或类似于操作系统进程中的“文本”段。它存储 每个类的结构,如运行时常量池、字段和方法数据,以及方法和构造函数的代码,包括类和实例初始化以及接口初始化中使用的特殊方法(2.9) 。
方法区域在虚拟机启动时创建. 虽然方法区域在逻辑上是堆的一部分 ,但简单的实现可能选择不进行垃圾收集或压缩它。该规范不强制要求方法区域的位置或用于管理编译代码的策略。方法区域可以是固定大小的,也可以根据计算的需要扩展,如果不需要更大的方法区域,也可以收缩。方法区域的 内存不必是连续的 。JDK1.7及之前的实现叫做永久代,包括类信息,常量,静态变量以及常量池。1.7将字符串常量池放在堆里了。主要在堆里开辟内存,隶属于堆,但是相互隔离。
JDK1.8改名为元空间,元空间不再虚拟机设置的内存(堆)中,而是使用本地内存。
HSDB jvm静态对象实例在放法区还是堆中?
HSDB: JVM中的Java对象? 解读HSDBtype explain type explain 字面量 文本字符串(代码中双括号包裹的字符串)
声明为final的常量
基本数据类型的表示及属性方法明符号引用 类符号引用:类的完全限定名
字段的名称和描述符
方法的名称和描述符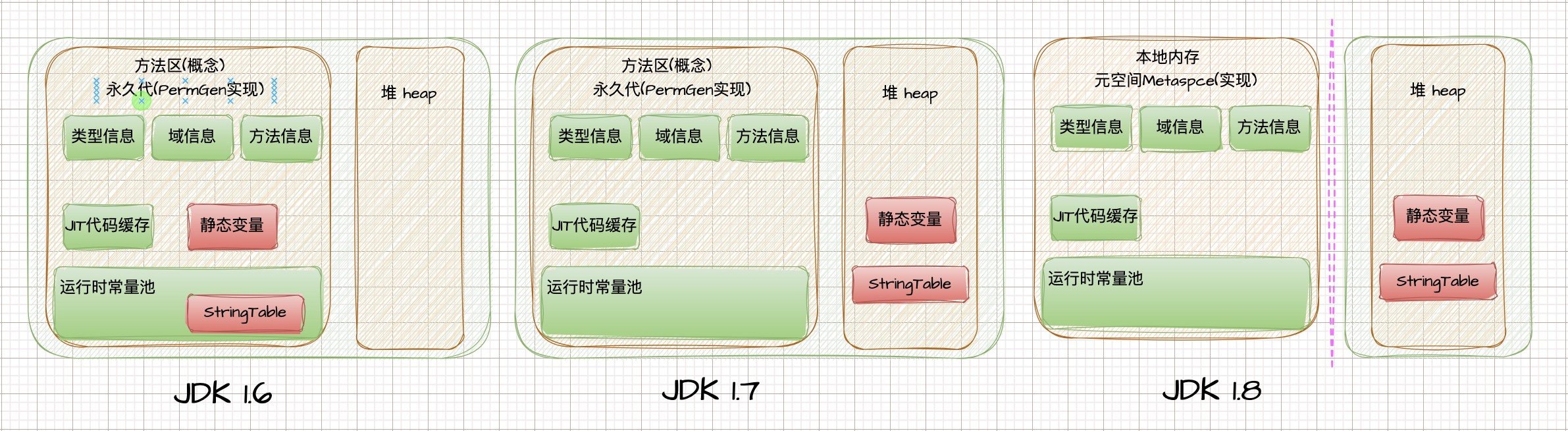
运行时常量池 #
JVMS: A run-time constant pool is a per-class or per-interface run-time representation of the constant_pool table in a class file (§4.4). It contains several kinds of constants, ranging from numeric literals known at compile-time to method and field references that must be resolved at run-time. The run-time constant pool serves a function similar to that of a symbol table for a conventional programming language, although it contains a wider range of data than a typical symbol table.
Each run-time constant pool is allocated from the Java Virtual Machine’s method area (§2.5.4). The run-time constant pool for a class or interface is constructed when the class or interface is created (§5.3) by the Java Virtual Machine.
翻译:运行时常量池是每个类或者接口运行时类文件中constant_pool表的表达形式。它包含几种常量,从编译时已知的数值字面量到必须在运行时解析的方法和字段引用。运行时常数池的功能类似于传统编程语言的符号表,尽管它比典型的符号表包含更广泛的数据。
每个运行时常数池都是从Java虚拟机的方法区分配的(2.5.4)。类或接口的运行时常数池是在Java虚拟机创建类或接口时构造的(5.3)。常量池 是方法区比较重要的一部分,分为以下几种:类文件常量池(静态常量池, 字节码文件解析 ), 字符串常量池,运行时常量池,
封装类常量池。类文件常量池中的数据在类加载的时候会放入到运行时常量池中,并将符号引用在解析阶段转换成运行时常量池中的直接引用。 并不是所有的符号引用都会解析成实体引用。比如 类文件常量池解析时机。
运行时常量池是属于JVM加载类时为每个类或者接口在方法区创建的。不属于堆,但里面引用的字符串字面量部分会在堆中或者字符串池中进行创建。 图感觉有误解: (字符串常量池在堆没问题,而且字符串引用也没问题。但是根据JVMS,运行时常量池是在方法区创建的。根据这张图展示的来说,字符串常量池就属于方法区了❌)。
运行时常量池中的所有引用最初都是符号性的.还有一些非符号引用的。string,integer,long获取运行时常量池中的数据 #
主要通过反射获取Class类中的Method
getConstantPool,然后结合实际类获取常量池sun.reflect.ConstantPool。 参考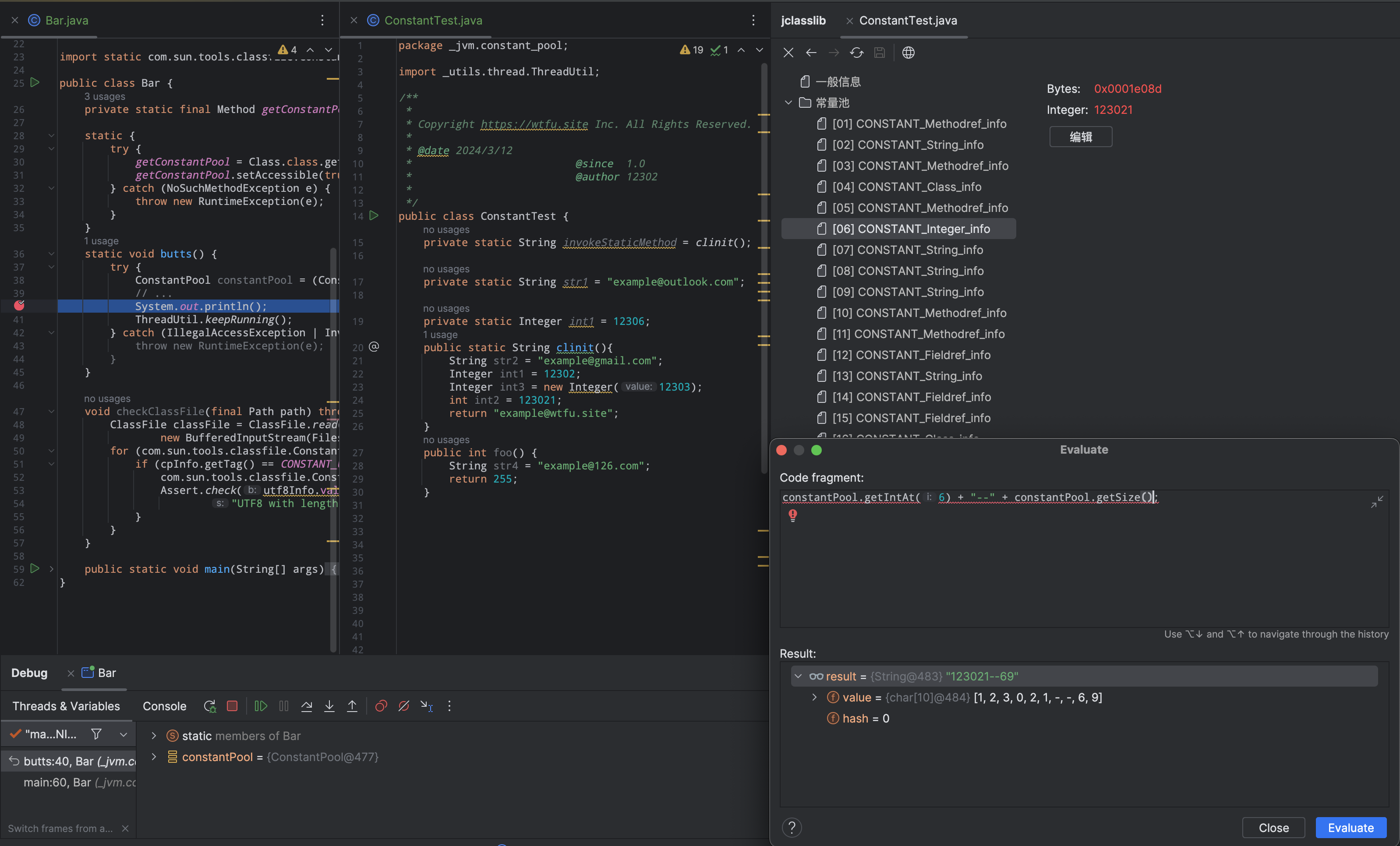
Warning
需要注意的是不知道为什么通过
constantPool.getStringAt(2)获取字符串常量的时候会导致JVM crash,有时候是好使的。暂时不知道原因。
错误信息如下:Problematic frame:# V [libjvm.dylib+0x1e732e] Array<unsigned short>::index_of(unsigned short const&) const+0x4类文件常量池解析时机 #
JVM加载类的时候并不是一上来就会将原来字节码文件中的常量池全部解析。比如下面这段代码,查看字面量确实存在
"example@126.com"。但是使用jvisualvmdumpheap后没有找到对应的字符串。字符串字面量,和其他基本类型的字面量或常量不同,并不会在类加载中的解析(resolve) 阶段填充并驻留在字符串常量池中,而是以特殊的形式存储在 运行时常量池(Run-Time Constant Pool) 中。而是只有当此字符串字面量被调用时(如对其执行ldc字节码指令,将其添加到栈顶),HotSpot VM才会对其进行resolve,为其在字符串常量池中创建对应的String实例。
具体来说,应该是在执行ldc指令时(该指令表示int、float或String型常量从常量池推送至栈顶)在JDK1.8的HotSpot VM中,这种未真正解析(resolve)的String字面量,被称为pseudo-string,以JVM_CONSTANT_String的形式存放在运行时常量池中,此时并未为其创建String实例。
在编译期,字符串字面量以"CONSTANT_String_info"+“CONSTANT_Utf8_info"的形式存放在class文件的 常量池(Constant Pool) 中;在类加载之后,字符串字面量以"JVM_CONSTANT_UnresolvedString(JDK1.7)“或者"JVM_CONSTANT_String(JDK1.8)“的形式存放在 运行时常量池(Run-time Constant Pool) 中;在首次使用某个字符串字面量时,字符串字面量以真正的String对象的方式存放在 字符串常量池(String Pool) 中。 参考来源一般来说,如果使用
String str4 = "example@126.com";之类的代码,肯定会将字面量"example@126.com"使用指令ldc从SCP加载,没有的话创建对象,然后给str4引用。但是目前通过工具分析出来的结果是代码马上执行完了,然后堆里面还没有创建相应的实例。所以并不是所有的constant_pool Table中的常量项都会即时解析。比如这种没有调用的情况。
另外分析整形数据。如果执行select i from java.lang.Integer i where i.value > 12302,只会出现12306类属性和12304当前帧栈两个对象。其他的数值可以理解为一个数字,退出帧栈就没了,有一个比较特殊int int2 = 123021;。根据 int 入栈指令以及 ldc [JVMS-6.5] 执行描述部分The run-time constant pool entry at index either must be a run-time constant of type int or float, or a reference to a string literal, or a symbolic reference to a class, method type, or method handle (§5.1). ,这个会执行ldc #6将这个int型从常量池中拿出来。与运行时常量池有关,需要注意。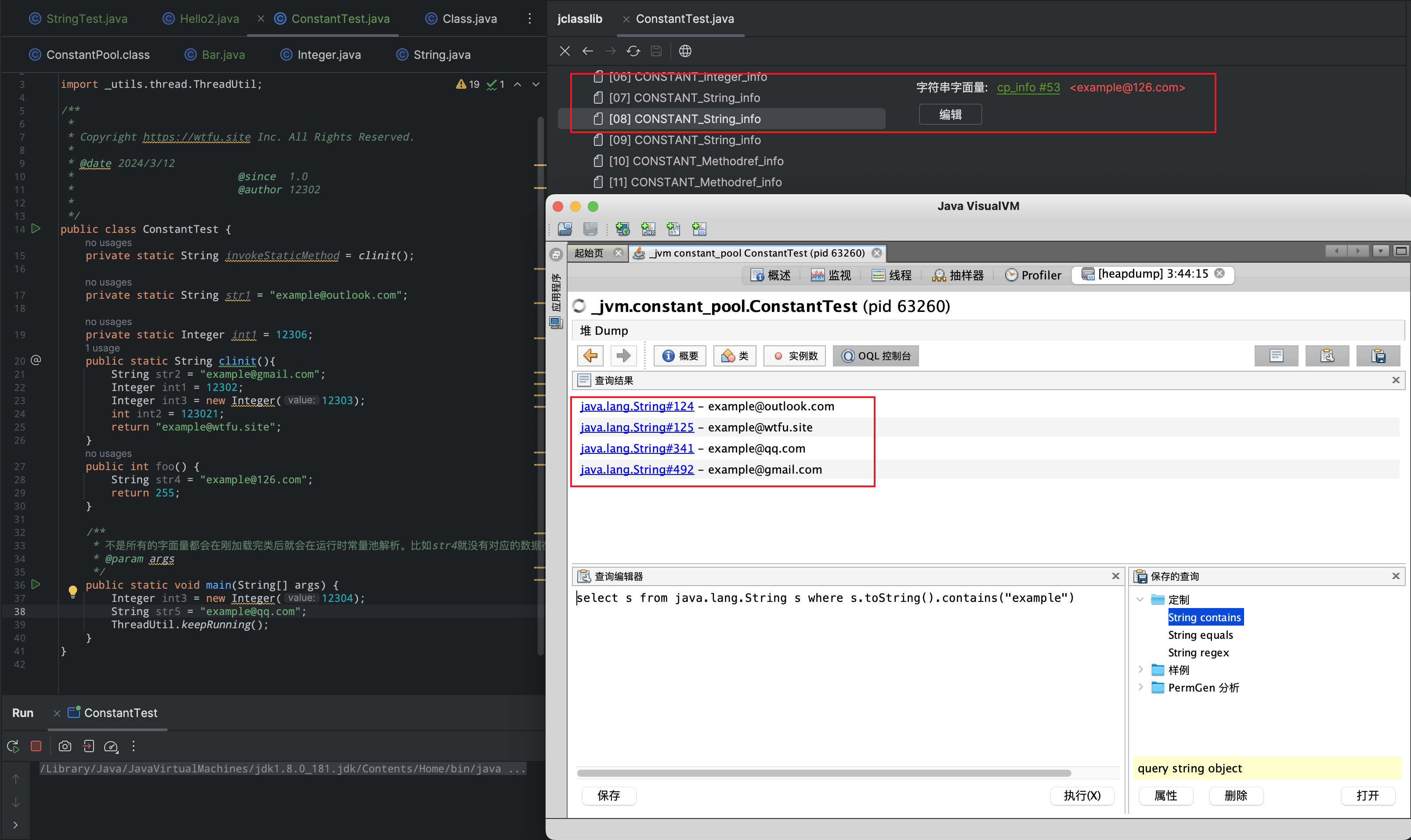
Reference #
- https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-2.html#jvms-2.5.5
- https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-6.html#jvms-6.5.ldc
- https://blog.csdn.net/qq_43210583/article/details/116558468
- https://juejin.cn/post/6844903655171178509
- https://stackoverflow.com/questions/28264012/im-curious-about-what-ldc-short-for-in-jvm
- https://www.cnblogs.com/mic112/p/15520770.html#字面量是什么时候进入到字符串常量池的
- https://cloud.tencent.com/developer/article/2110482
虚拟机栈 #
运行过程可以参考 一个类运行的全过程
局部变量表 #
帧栈中,有局部变量表来存储数据,包括参数,所需的内存空间在编译期间就确定了。
存储单位是Slot【32bi t】,一个slot就是JVM规范对局部变量区里存储一个局部变量的存储单元的叫法。每个slot可以存储一个宽度在32位或以下的原始类型值,或者一个引用,或一个returnAddress;相邻的两个slot可存储一个double或long型的值。 参考,另外参考中也有例子体现slot复用性。
根据索引的方式定位局部变量表,下标从0开始。非静态方法的0位是this,静态方法的从参数开始排列
slot复用: 影响GC。当同一个帧栈中局部方法中变量没有被复用,会导致无法垃圾回收。操作数栈 #
先进后出的数据存储结构,可以存储任意的Java数据类型。用来进行算数运算,参数传递及临时存储
栈顶缓存技术。操作数在内存中,频繁操作影响性能。可以将栈顶全部元素缓存在物理CPU寄存器中动态链接 #
方法返回地址 #
Comment
本地方法栈 #
类比虚拟机栈,不过这个是针对本地语言(c/c++),方法一般由native修饰。
程序计数器 #
一块比较小的内存空间,可以看做事当前线程所需执行字节码的行号指示器,通常由执行引擎开执行程序计数器所指向的行号内容。更确切的说。一个线程的执行,是通过字节码解释器改变当前线程 的计数器的值,来获取下一条需要执行的字节码指令,从而确保线程的正确执行。
堆 #
垃圾回收算法 #
Mark-Sweep(标记-清除) #
Comment
回收过程主要分为两个阶段,第一阶段为追踪(Tracing)阶段,即从GCROOT开始便利对象图,并标记(Mark)所遇到的每个对象,第二阶段为清除(Sweep)阶段,即回收器检查堆中的每一个对象,并将未标记的对象进行回收,整个过程不会发生对象移动。整个算法再不同的实现中会使用三色抽象(Tricolour Abstraction),位图标记(BitMap)等技术来提高算法的效率,存活对象较多时较高效。
Mark-Compact(标记-整理) #
Comment
这个算法主要的目的就是解决在非移动式回收器中都会存在的碎片化问题,也分为两个阶段,第一阶段与Mark-Sweep类似,第二阶段则会对存活对象按照整理顺序(Compaction Order)进行整理。主要实现有双指针(Two-Finger)回收算法,滑动回收(Lisp2)算法和引线整理(Threaded Compaction)算法等。
Copying(复制) #
Comment
将空间分为两个大小相同的From和To两个半区,同一时间只会使用其中一个。每次进行回收时将一个半区的存活对象通过复制的方式转移到另一个半区。有递归(Robert R.Fenichel 和 Jerome C.Yochelson提出)和迭代(Chenev提出)以及解决了前两者递归栈,缓存行等问题的近似优先搜索算法。复制算法可以通过碰撞指针的方式进行快速地分配内存,但是也存在着空间利用率不高的缺点,另外就是存活对象比较大时复制的成本较高。
Generational(分代) #
垃圾回收器 #
Tip
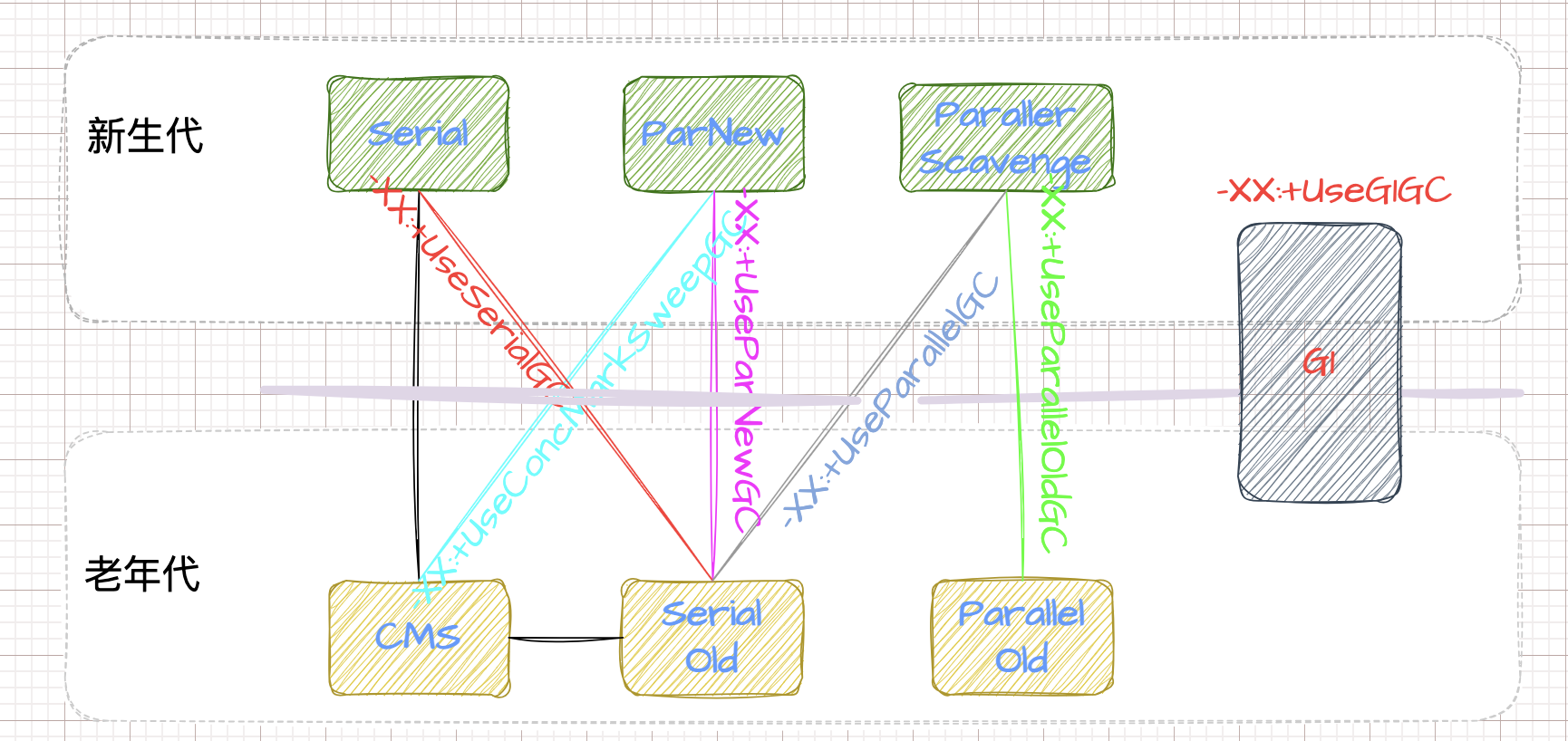
Ref:ParNew 和 PSYoungGen 和 DefNew 是一个东西么?
是这样的。 串行收集器: DefNew:是使用-XX:+UseSerialGC(新生代,老年代都使用串行回收收集器)。 并行收集器: ParNew:是使用-XX:+UseParNewGC(新生代使用并行收集器,老年代使用串行回收收集器)或者-XX:+UseConcMarkSweepGC(新生代使用并行收集器,老年代使用CMS)。 PSYoungGen:是使用-XX:+UseParallelOldGC(新生代,老年代都使用并行回收收集器)或者-XX:+UseParallelGC(新生代使用并行回收收集器,老年代使用串行收集器) garbage-first heap:是使用-XX:+UseG1GC(G1收集器).
垃圾回收器优缺点
参考1, 参考2中好像ParallelGC和ParallelOldGC描述反了。名称 模式 分代 说明 Serial 串行 新 单线程串行收集器 ParNew 并行 新 serial 的并行版本 Parallel Scavenge 并行 新 不同体系,并行吞吐量优先。可以通过参数来打开自适应调节策略,
虚拟机会根据当前运行情况收集性能监控信息,
动态调整这些参数以提供最合适的停顿时间或最大的吞吐量,
可以通过参数控制GC时间范围或者比例。Parallel Old 并行 老 针对PSScavenge的老年代收集器 Serial Old 串行 老 serial老年代 CMS 并发 老 并行最短时间收集器 G1 并发/并行 新/老 面向局部收集和基于Region内存布局的新型低延时收集器 Serial #
单线程收集器,收集时会暂停所有工作线程(stop the world,简称STW),使用复制收集算法,虚拟机运行在client模式时默认的新生代收集器。
最早的收集器,单线程进行GC
New和Old都可以使用。
新生代采用复制算法,老年代采用Mark-Compact算法。
因为是单线程工作,没有多线程切换的额外开销,简单实用。ParNew #
ParNew收集器就是Serial的多线程版本,除了使用多个收集线程外,其余行为包括算法,STW,对象分配规则,回收策略等都与Serial收集器一模一样。
对应的这种收集器是虚拟机运行在Server模式的默认新生代收集器,在单CPU的环境中,ParNew并不会比Serial有很好的效果。
使用复制算法(仅对新生代)
只有在多CPU的情况下,效率才会比Serial高。
可以通过-XX:ParallelGCThreads来控制GC线程数的多少。需要结合具体的CPU个数Parallel Scavenge #
Parallel Scavenge收集器也是一个多线程收集器,也是使用复制算法,但它的对象分配规则和回收策略都与ParNew收集器有所不同,它是以吞吐量最大化(即GC时间占总运行时间最小)为目标的收集器实现,它允许较长时间的STW换取总吞吐量最大化。
Serail Old #
Serial Old是单线程收集器,使用标记-整理算法的老年代收集器
Parallel Old #
老年代版本吞吐量优先的收集器,使用多线程和标记-整理算法,JVM 1.6 提供,在此之前,新生代使用PS收集器的话,老年代除了Serial Old外别无选择,因为PS无法与CMS收集器配置工作。
Parallel Scavenge在老年代的实现
PS + PO = 高吞吐量,但GC停顿时间可能不理想。CMS #
CMS(Concurrent Mark-Swap) 是一种以最短停顿时间为目标的收集器,使用CMS并不能达到GC效率最高(总GC时间最小),但它能尽可能降低服务的停顿时间,使用的是标记-清除算法。
追求最短停顿时间,非常适合web应用
只针对老年区,一般结合ParNew使用
GC和用户线程并发(尽量并发)
使用-XX:UseConcMarkSweepGC打开
牺牲CPU资源来减少用户线程的停顿。当CPU个数少于4的时候,有可能对吞吐量影响非常大
CMS在并发清理的过程中,用户线程还在跑,这时候需要预留一部分空间给用户线程
会带来碎片化问题,碎片过多很容易触发Full GC。
1、初始标记(CMS initial mark)2、并发标记(CMS concurrent mark)3、重新标记(CMS remark)4、并发清除(CMS concurrent sweep)
扩展 #
JVM部分参数 #
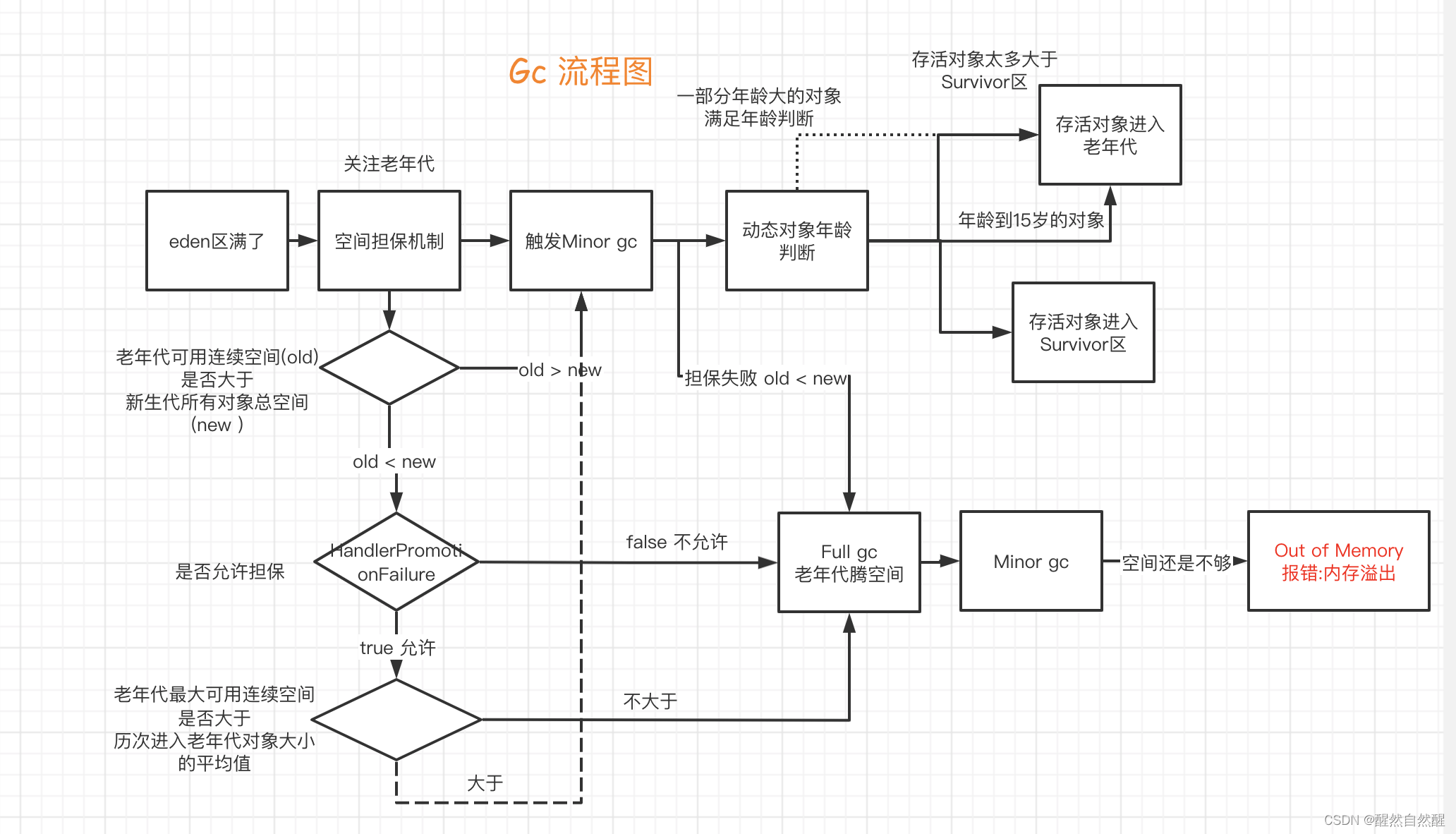
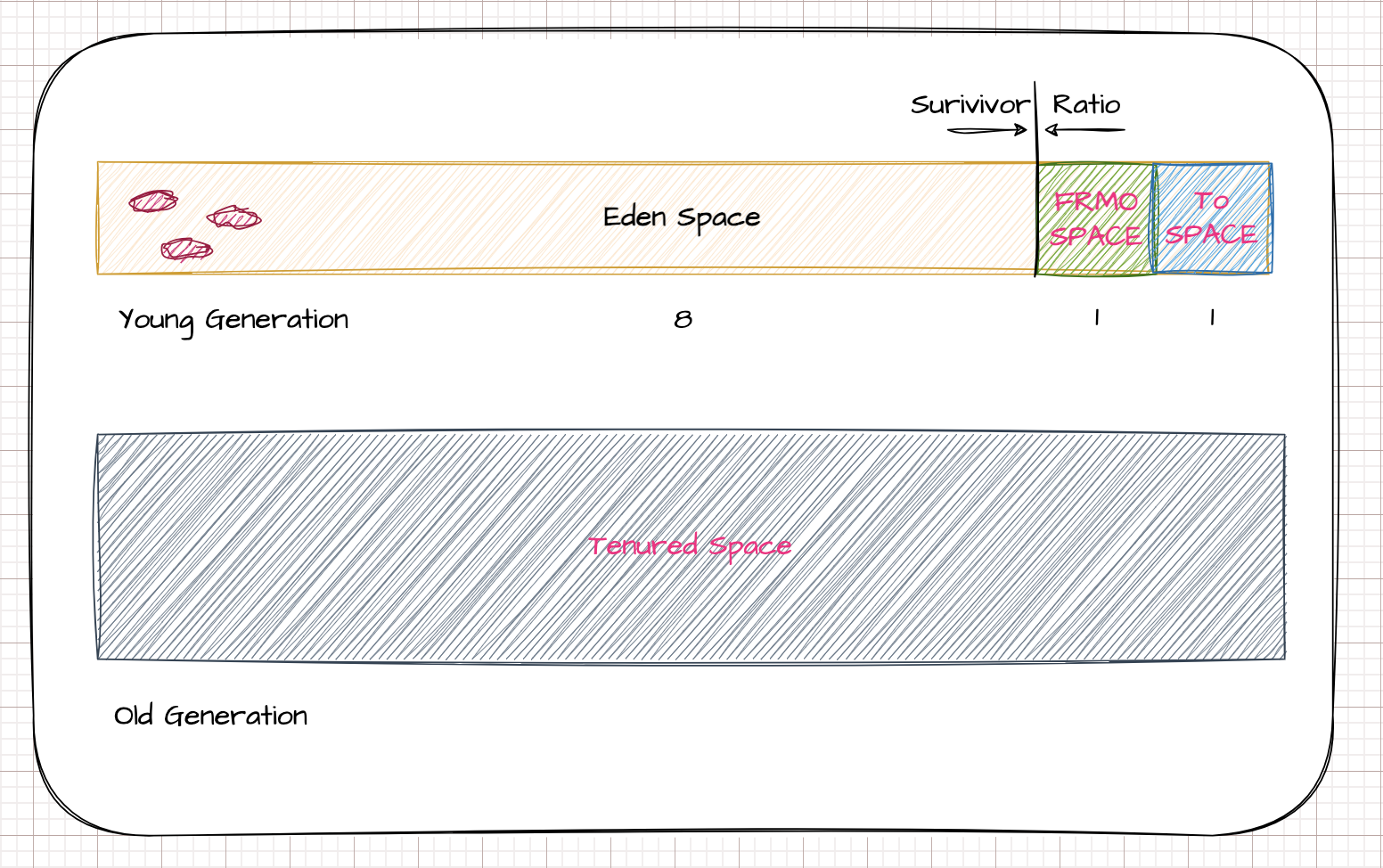
index explain -Xmx2g堆最大值 -Xms2g初始堆大小 -Xmn1g年轻代大小,在堆内存固定的情况下,年轻代和老年代成反比 -Xss128k线程栈大小 -XX:NewSize=1024m年轻代初始值 -XX:MaxNewSiz=1024m年轻代最大值 -XX:PermSize=256m持久代初始值 -XX:MaxPermSize=256m持久代最大值 -XX:NewRatio=4年轻代(eden, form,to)和年老代的比值 -XX:SurvivorRatio=4设置survivor区和eden比值 -XX:MaxTenuringThreshold=7对象年龄晋升阈值 新生代到老年代的标准 #
GCROOT 对象 #
- 每个帧栈 局部变量表
- 常量池中引用的对象。
- 方法区中静态变量引用的对象。
finalize 方法 #
同一个版本的垃圾回收器 #
同一个版本的垃圾回收器 JDK。 在不同的平台上使用的垃圾回收器不一样
使用下列命令查看:java -XX:+PrintGCDetails -XX:+PrintCommandLineFlags -versionmac
-XX:+UseParalleGC = PSYoungGen + ParOldGen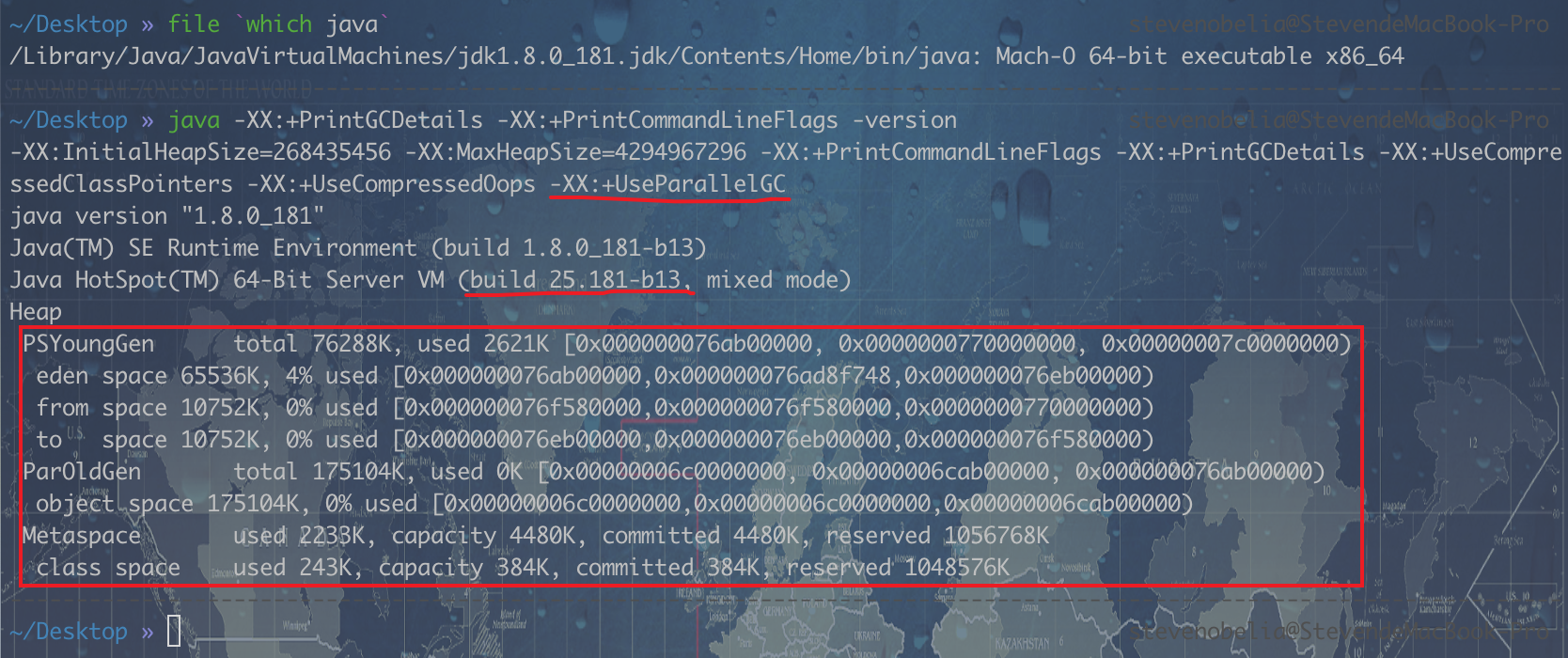
centos
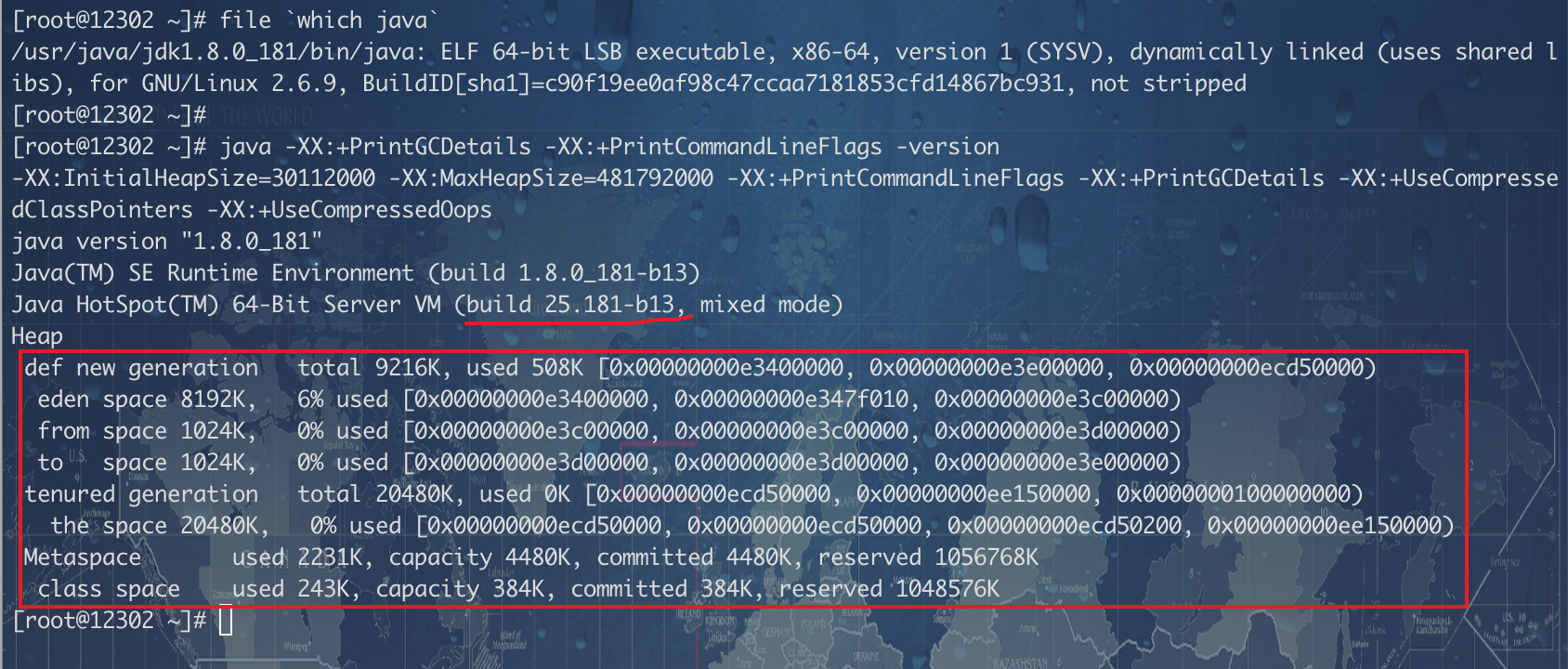
-XX:+UseParallelGC / -XX:-UseParallelOldGC选项 link
使用ParallelGC 并不一定在新生代和年老代都使用并发收集,也就是【ps+po】,也有可能是老年代使用单线程收集,如下官网解释。
Parallel compaction is a feature that enables the parallel collector to perform major collections in parallel. Without parallel compaction, major collections are performed using a single thread, which can significantly limit scalability. Parallel compaction is enabled by default if the option -XX:+UseParallelGC has been specified. You can disable it by using the -XX:-UseParallelOldGC option.
[Inside HotSpot] UseParallelGC和UseParallelOldGC的區別
GC类型: #
minorGC,majorGC/FullGC. 参考 新生代GC(minor GC),GC非常频繁,回收速度比较快
老年代GC(majorGC/FullGC),发生在老年代的GC,出现了 major GC经常 伴随至少一次minorGC(并非绝对),major速度一般比minor慢10倍以上。
-XX:+PrintGCDetails #
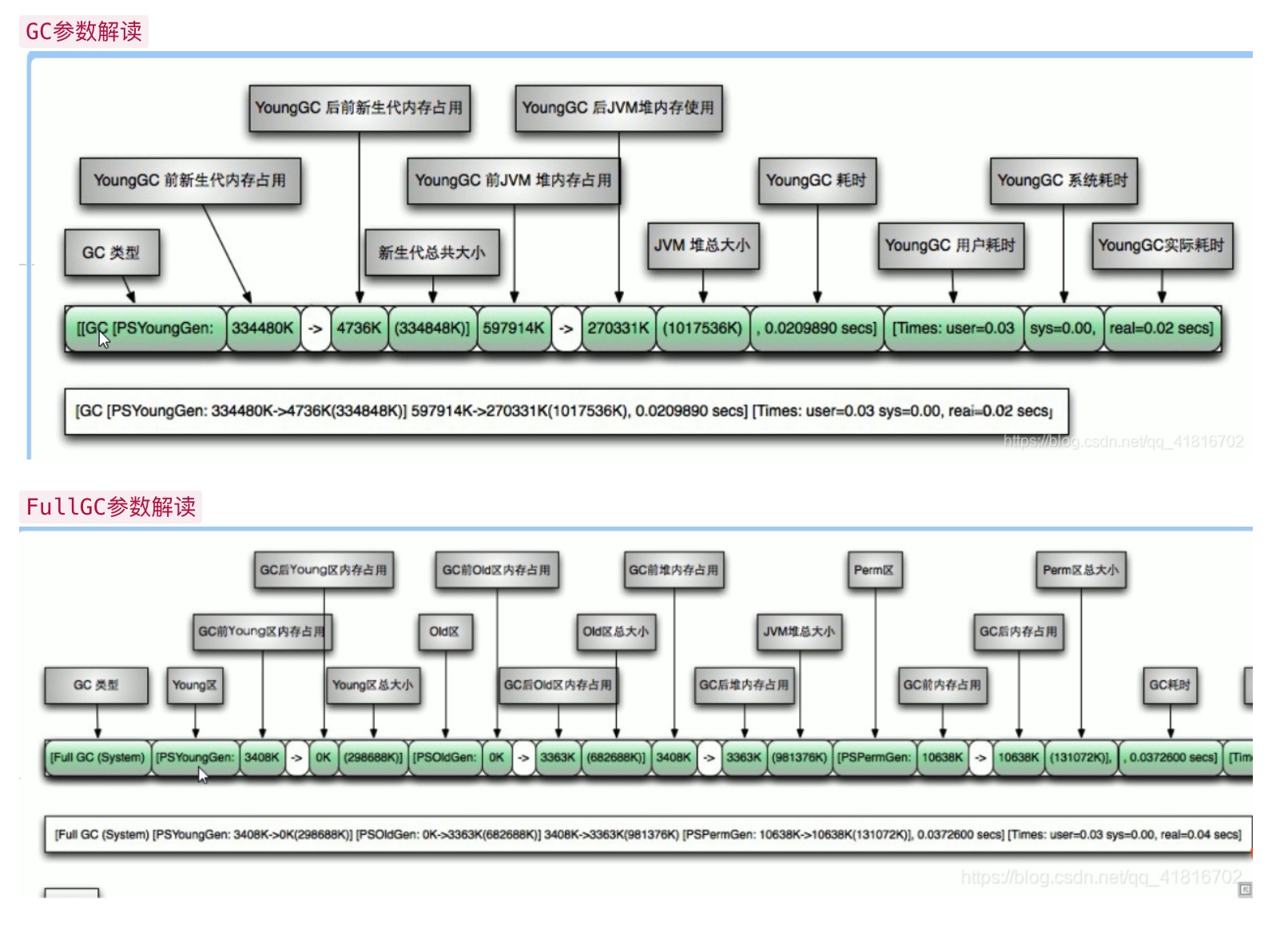
永久代回收 #
回收的对象是废弃的常量及无用的类
卡表 #
jvm 进行GC的时候有一种特殊情况,比如老年代引用了新生代的对象,俗称跨代引用。这样只按照GCROOT进行标记的话,跨代引用对象肯定就干掉了。所以jvm引入了一个新概念叫记忆集,在hotspot实现中叫卡表(CardTable,简单字节数组),将整个堆划分为多个卡页(card page)一般512字节[2^9]。当堆中存在跨代引用时,将此卡页对应卡表下表中的值置为1,也就是脏页。这样,GC回收的时候除了GCROOT,也对脏页中的对象进行扫描。避免全堆扫描。
如何判断对象是那个代的?
估计跟对象头有关。比如对象头中的年龄。对象分配位置或者地址引用。既时编译JIT(Just-in-time compilation) #
java为了实现一次编译,处处运行。将编译分为两部,首先它由javac 编译成中间代码-字节码。然后由解释器逐条将字节码解释为机器码[本地代码]来执行。所以在性能上Java通常不如C++这样的编译类型语言。为了优化Java的性能。JVM在解释器之外引入了即时(just in time)编译。先由解释器解释执行,达到阈值后,编译成字节码,存入codeCache中。当下次执行,再遇到这段代码,就会从codeCache中读取机器码,直接执行。
-Xint解释执行-Xcomp编译执行JVM1.8 Macon 默认 mixed .混合执行。
JIT优化技术 #
逃逸:指的是变量引用是否被其他方法或者线程访问。 -XX:+DoEscapeAnalysis。 记忆中的B站视频。相关JVM参数可以 参考
- 栈上分配
- 标量替换/分离对象
- 锁消除
SafePoint #
LTAB(Thread Local Allocation Buffer) #
常见问题及调优 #
由于编写的Java类数量太多导致
PermGen OutOfMemoryError一次是某公司的超大型Java程序,导致PermGen OutOfMemoryError,那是JDK1.6,原因很简单,编写的Java类数量太多了,撑爆了默认的128M的永久代。解决方法很简单,改成更大的512M(参数名叫啥已经忘了,因为新版JVM没有PermGen限制了)。但是根本问题不是出在JVM,而是代码太垃圾,Java类的数据超多造成的。
CPU 100% 问题排查
Comment
1 在Linux上面使用
top命令进程查询 CPU100% 进程ID[pid],此处为23198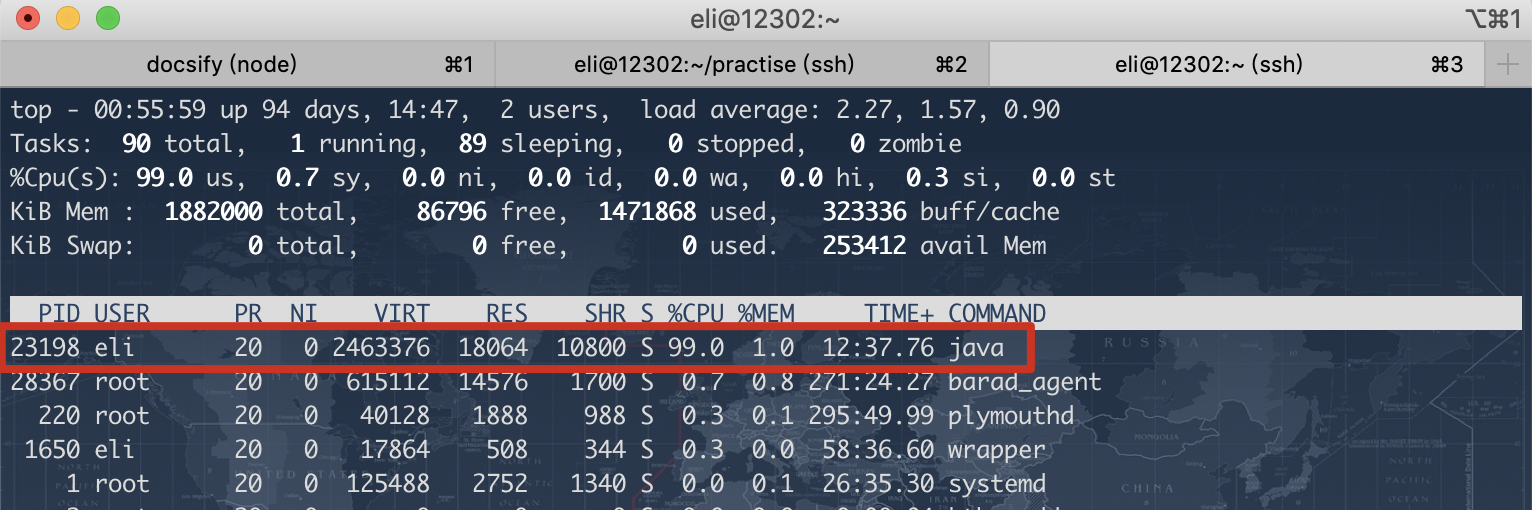
Comment
2 使用
top -Hp 23198查看具体线程所占用CPU,然后将线程通过printf "%x\n" 23208记录线程ID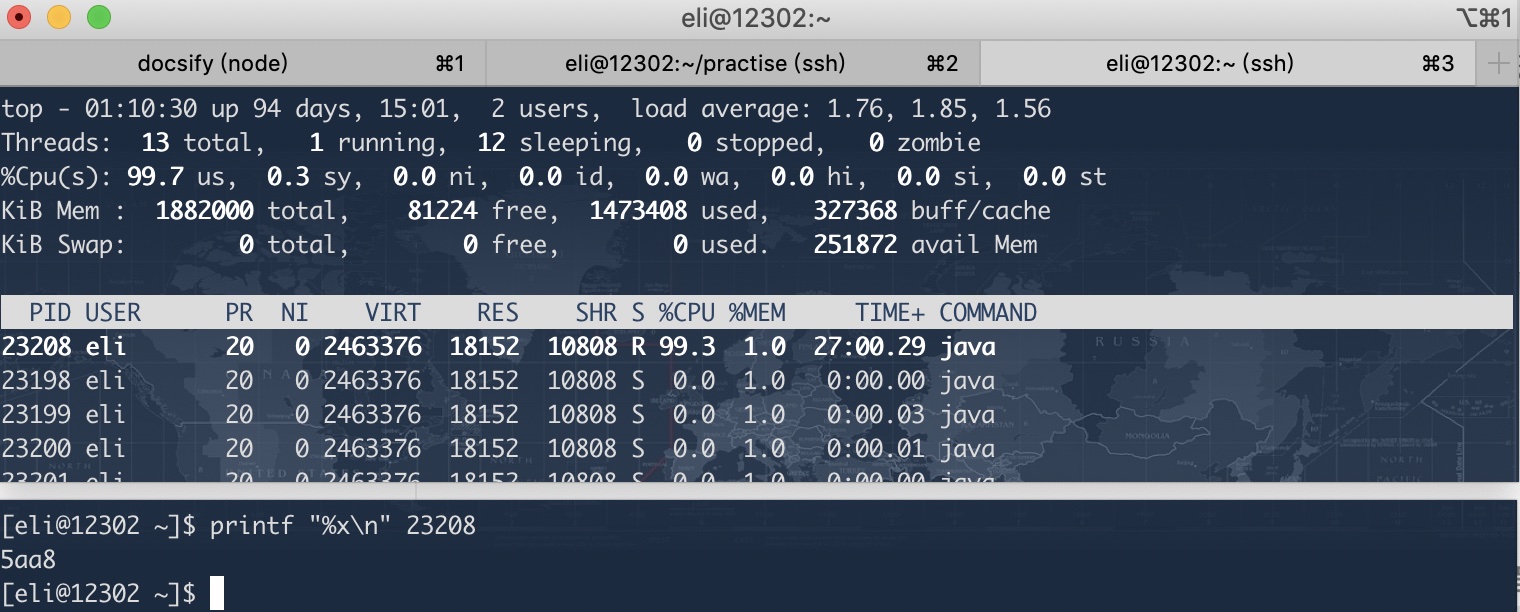
Comment
3 使用
jstack 23198打印进程下线程状态。根据上一步获取的十六进制的线程ID 查找是那个线程栈导致。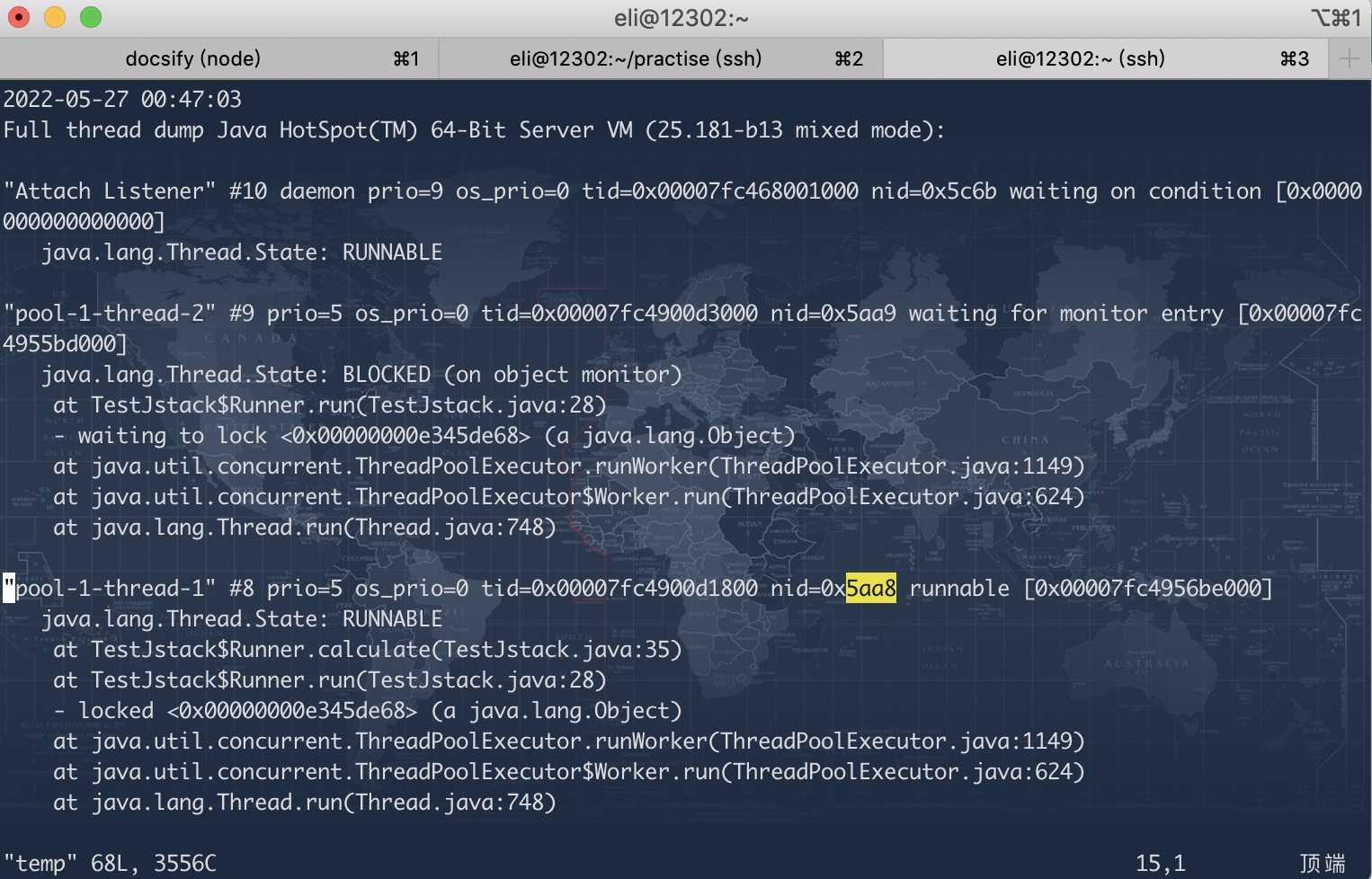
内存超标
频繁FGC导致线上程序运行缓慢
面试官问数据量多大
Reference #